The user manager lets you configure folders that point at different locations. These can be a local folder on the HD or a network share that is still part of the file system, or a remote filesystem.
The new remote item button will let you make a new item, or you can right click and get properties on an existing item.
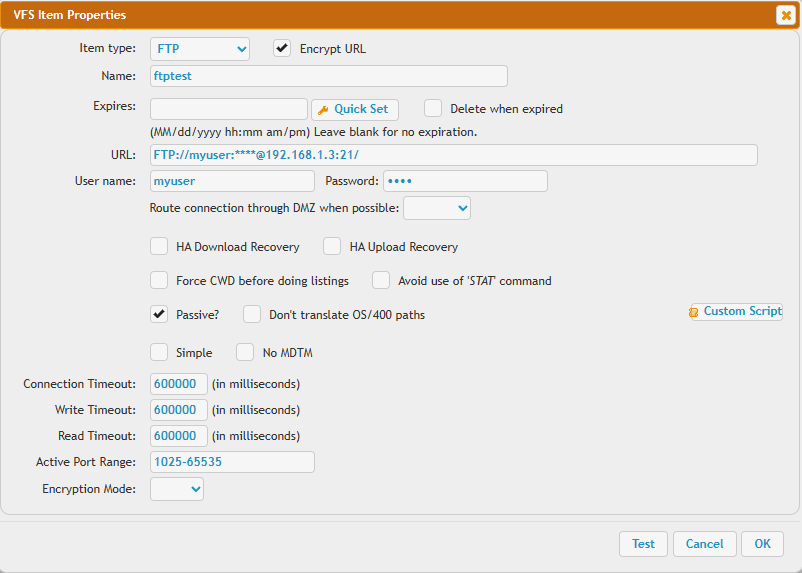
You can configure FTP, or SFTP connections here to other backend servers. Users interacting with your server won't know the real files are located on another server. So using this you can make CrushFTP act as a backend proxy to a separate server. An example is the FTPProxy scenario.
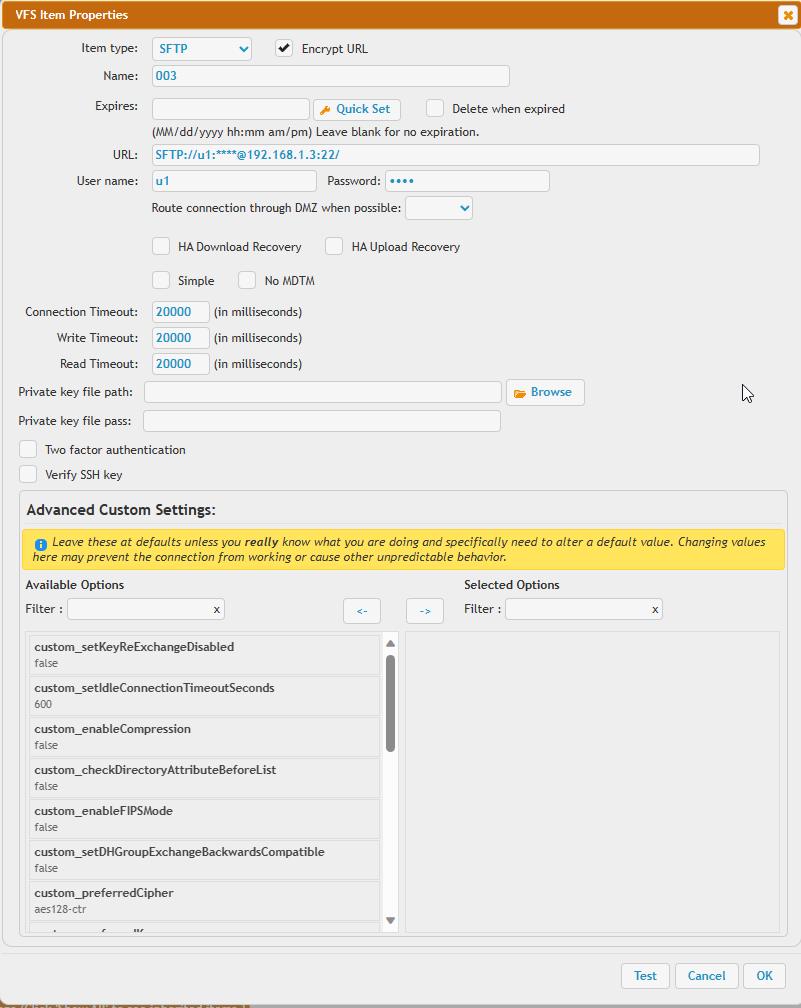
SFTP allows you to configure a private key for authentication too as well as doing two factor authentication.
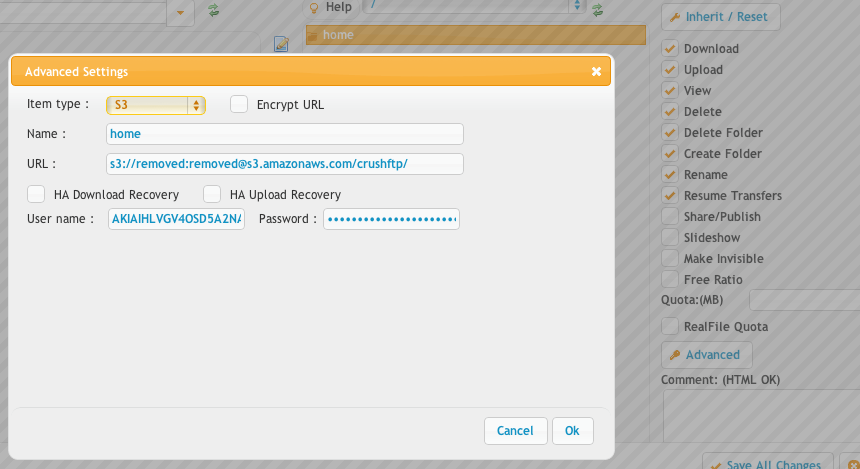
If you are planning to use the Amazon S3 service for backend storage, you can do so as well. See the below example for how to configure the connection. If you specify a path on the end of the URL that is the bucket to use, and folders to use. In my example i am specifying the crushftp bucket.
If you are planning on integrating CrushFTP with Azure you can follow Azure Integration.
CrushFTP supports many different protocols for the VFS that a user can access.
FILE://#
This is your standard type of folders on your local drives. This could also reference a UNC location on windows if the service is running as a domain user that can access the UNC locations.FTP:// FTPS:// FTPES://#
This allows you to use a remote FTP server as the VFS for a user. Some people use an already established IIS FTP server as the back end, but put CrushFTP as the front end giving more controls and protocols.SFTP://#
This allows you to use a SFTP server as the back end. OpenSSH on a Linux server is often used as the back end.SMB://#
This allows you to connect to a Samba or Windows file server as the backend and provide the credentials. Usually in the format of "smb://domain\user:pass@servername/share/" or "smb://user@domain.com:pass@servername/share/".HTTP:// HTTPS://#
This allows you to point to another CrushFTP server and use that as the back end. The HTTP methods used are only valid to another CrushFTP server. It uses specific calls a CrushFTP server expects for file management.WEBDAV:// WEBDAVS://#
This allows you to use a standard webdav server as the back end. It makes all the queries about files and dir listings using the webdav XML calls.GDRIVE://#
Allows you to use google drive resources with Crush as the front end. Initial setup is not for the faint of heart though. GDriveSetupRFILE://#
Special VFS method that launches new "shells" impersonating the user logging in. Its not super fast, and has a lot of overhead, but some unique scenarios need this method of impersonation if the SMB:// method doesn't work for them.MEMORY://#
Implements a VFS in memory, but if the server is restarted, all the data disappears too. Temporary usage, and frequently just for special cases in Jobs.S3://#
Allows you to use a S3 bucket as the backend filesystem. However since S3 isn't hierarchical, you only get simulated folders, and no ability to rename, and some other gotchas about how S3 works. These aren't limitations we impose, but just due to the design decisions S3 made in that its intended for static item consumption and not as a location for holding and manipulating file names.We support the IAM auth scenario too, its just not the default mode. Setting the S3 username to "iam_lookup" and S3 password to "lookup" will use this method.
The following policy permissions are needed on S3:
s3:GetBucketLocation s3:ListAllMyBuckets s3:ListBucket s3:ListBucketMultipartUploads s3:PutObject s3:AbortMultipartUpload s3:ListMultipartUploadParts
S3CRUSH://#
This still uses an S3 bucket for storage, however we only use S3 as the storage for the object. We hold a special "s3" folder on the CrushFTP server which has the folder structure simulated, and "file" items which are XML pointers to the real S3 data. The difference is its *much* faster than the normal S3 since dir listings are fast, renames are instantaneous, etc. It uses S3 in the way it was designed for. The downside though is that if you make changes to the data in S3 and don't go through CrushFTP, now CrushFTP doesn't know what your data is in S3...you are out of sync, and technically "corrupted". So if you want to use S3 and have a fast and unlimited storage solution, S3Crush is perfect for that if you won't be changing the data from another tool that hits the bucket directly.Add new attachment
List of attachments
| Kind | Attachment Name | Size | Version | Date Modified | Author | Change note |
|---|---|---|---|---|---|---|
png |
ftp_example.png | 28.6 kB | 2 | 31-Aug-2023 23:44 | Sandor | |
png |
new_remote.png | 9.7 kB | 1 | 29-Dec-2020 05:25 | Ben Spink | |
png |
s3_example.png | 76.7 kB | 1 | 29-Dec-2020 05:25 | Ben Spink | |
png |
sftp_example.png | 51.0 kB | 2 | 31-Aug-2023 23:44 | Sandor |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
- WebInterface
- Server Admin
- User Manager
- Client Apps
- CrushBalance Load Balancer
- High Availability
- Self Registration
- Preferences
- Email Templates
- Restrictions
- Replication
- Banning
- Logging
- Encryption
- Alerts
- Folder Monitor
- Tunnels
- Syncs
- User Config
- Search Config
- Preview
- Misc
- Plugins
- FAQ
- API
- Linux Install
- Virtual Linux Server
- Server Variables
- Google Authenticator and Microsoft Authenticator