Enterprise-only feature, not available with Normal licenses.
#
A set of features to facilitate clustering. It allows independently to keep in sync the local user database, server preferences, Jobs and replicate file operations issued by user accounts, automation Events and Jobs. The two subfeature sets work independently from each other.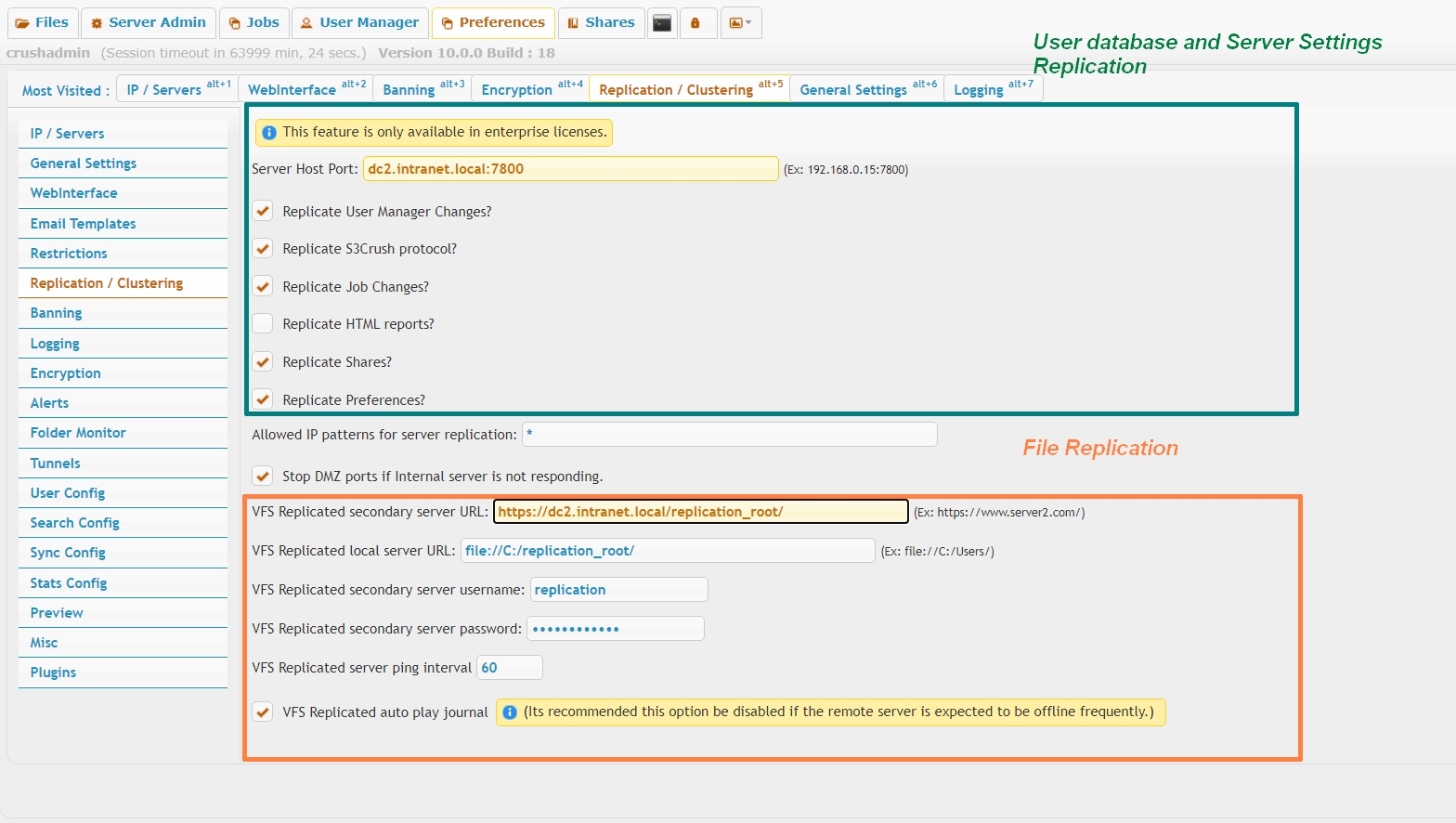 |
User database and Server settings replication
#
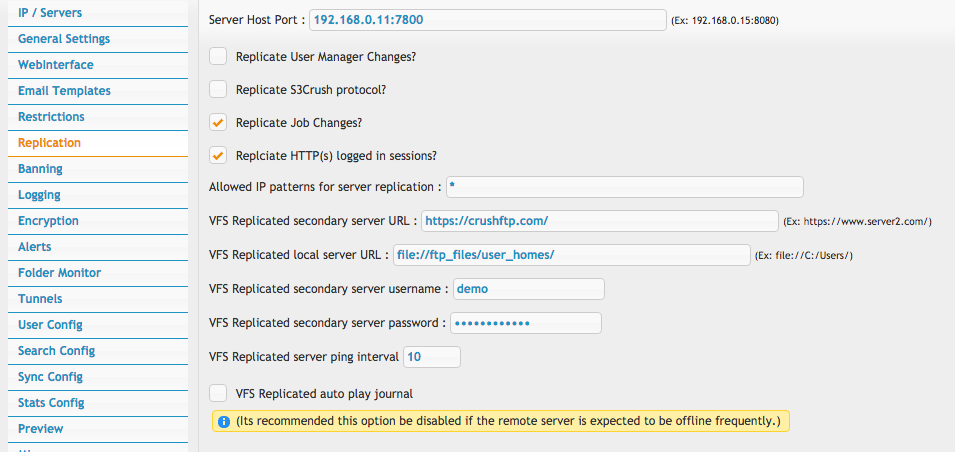
Configured on the upper half of the page (green highlight). Each cluster node must be point towards the other node(s) IP or hostname and replication port. Network firewall between nodes must allow two ways traffic on the replication port.The checkboxes toggle replication of server components. IP port bindings and the replication settings themselves are excluded from replication.
- Server Host Port
- IP (or hostname) port pair, pointing to the mirror server node. In case of more than 2 nodes clustered, the field accepts comma separated list of all other nodes' IP port pair.
- Replicate User Manager Changes
- toggle replication of the local XML user database. If using an external SQL database, this option has to be turned off.
- Replicate S3Crush protocol
- applies only when using the s3crush:// VFS protocol. Toggles replication of the local S3 database. Needs to be turned off when using default s3:// VFS protocol. In all other scenarios, ignored.
- Replicate Job Changes
- toggle replication of Jobs. Need to complement with ServerBeat, to prevent all cluster nodes running the same jobs concurrently.
- Replicate HTML reports
- toggle replication of scheduled Reports.
- Replicate Shares
- toggle replication of temporary accounts
- Replicate Preferences
Files Replication:#
(This is not a common scenario and should be used in rare cases.)The items starting with "VFS" are what applies to this. The secondary server URL is the URL on the other CrushFTP server. So generally it will be "https://server2.com/".
The local server URL is a path locally that is the base location for all replication. This same exact path needs to exist on the opposite server.
The username and password is what will be used when authenticating to the other server to do file transfers. Typically a username like 'replication' is appropriate here. That user needs to exist on both servers, having the same access to the local folder defined in step 2. This user needs to allow all protocols...not that it will use all protocols, but it will cause replication delays if the user is locked down to only HTTP(S) for example.
The ping interval is how often to check if the server is online if there are pending journal items and the server is offline.
The VFS auto play function should be disabled for this. If its enabled, it will slow down user interaction with a server that is online if the opposite server is down. If enabled, on every interaction with a folder or file transfer or rename and so on, it tries to re-play the journal for pending items...you don't want that. Turn it off. If a server is down, and automated process will play the journal at the ping interval checking for when the server comes back online.
User Manager#
Now its time to configure the User Manager.
We need the replication user created, giving them access to the base folder, with full access, and *without* the replication checkbox enabled. That is critical. If its enabled, it would create a circular loop.
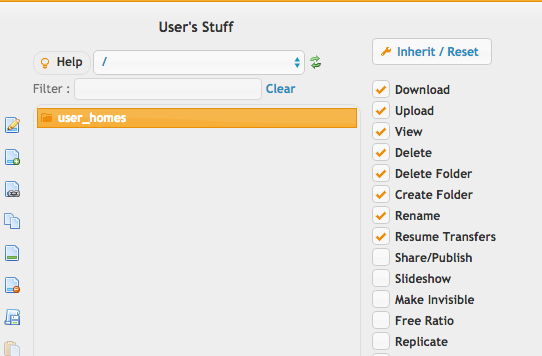
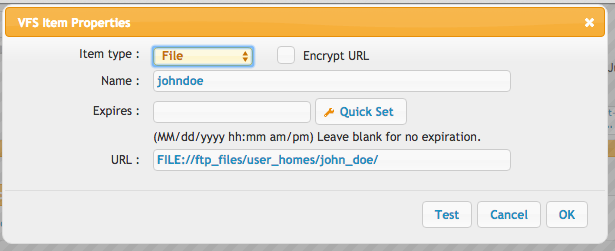
Next we need to give a user access to a folder inside that user_homes area...
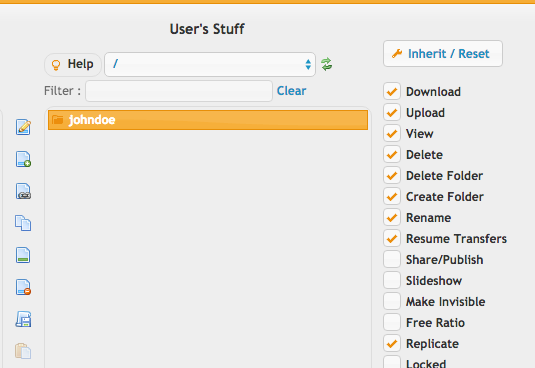
...and on their folder, enable the replication checkbox.
How it Works#
Changes that john doe makes to their folder are now replicated to the server configured replication server.The journaled entries are stored in a folder called "multi_journal" in your main CrushFTP folder. The folder structure contains a hash of the VFS item being used as a folder name to group items to the same VFS location. There will always be the one location. In this are time stamped folders for the changes being made. Each time stamped folder has a config.XML file describing the change and parameters needed to replicate that change. If the change is an upload, there is also a single file called "upload" which is the binary dump of the data being uploaded. While an upload is in progress, this file is written to in parallel so that if the transfer breaks to the remote side, we have the whole file in the journal to utilize in replicating it. If the file upload completes successfully, the file is immediately purged from the journal as well.
Troubleshooting#
If the opposite server goes offline, this folder will start to fill up with uploads that are pending to be delivered to the opposite server. If there is a conflict scenario where a replicated action cannot be performed on the opposite server, you will have to manually look through this folder, sorted by date, and decide what to do with the replication item that cannot be processed.Add new attachment
Only authorized users are allowed to upload new attachments.
List of attachments
| Kind | Attachment Name | Size | Version | Date Modified | Author | Change note |
|---|---|---|---|---|---|---|
png |
»john_doe.png | 46.6 kB | 1 | 05-Dec-2023 05:32 | Ben Spink | |
png |
»replication.png | 107.6 kB | 2 | 05-Dec-2023 05:32 | Ben Spink | |
jpg |
»replication1.jpg | 374.8 kB | 1 | 05-Dec-2023 05:32 | Ada Csaba | |
jpg |
»replicationdbg.jpg | 239.5 kB | 1 | 05-Dec-2023 05:32 | Ada Csaba | |
png |
»user_homes.png | 46.8 kB | 1 | 05-Dec-2023 05:32 | Ben Spink | |
png |
»vfs_properties.png | 38.9 kB | 1 | 05-Dec-2023 05:32 | Ben Spink |
«
This particular version was published on 05-Dec-2023 05:32 by Ada Csaba.
G’day (anonymous guest)
Log in
CrushFTP11 | What's New

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- WebInterface
- Server Admin
- User Manager
- Client Apps
- CrushBalance Load Balancer
- High Availability
- Self Registration
- Preferences
- Email Templates
- Restrictions
- Replication
- Banning
- Logging
- Encryption
- Alerts
- Folder Monitor
- Tunnels
- Syncs
- User Config
- Search Config
- Preview
- Misc
- Plugins
- Manage Shares
- PGP
- Telnet
- FAQ
- API
- Linux Install
- Virtual Linux Server
- Server Variables
- Google Authenticator and Microsoft Authenticator
- AS2 EDI
JSPWiki